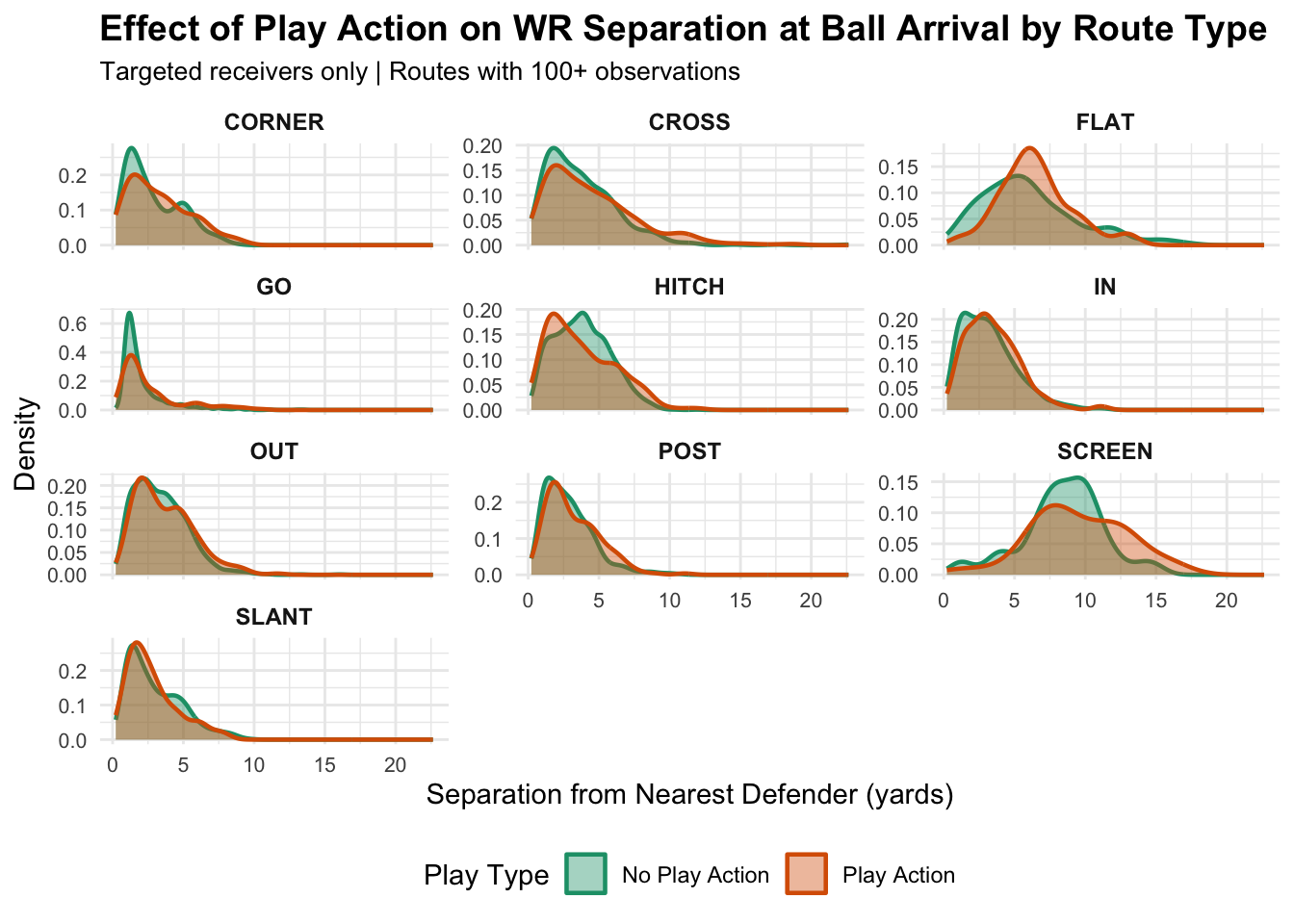
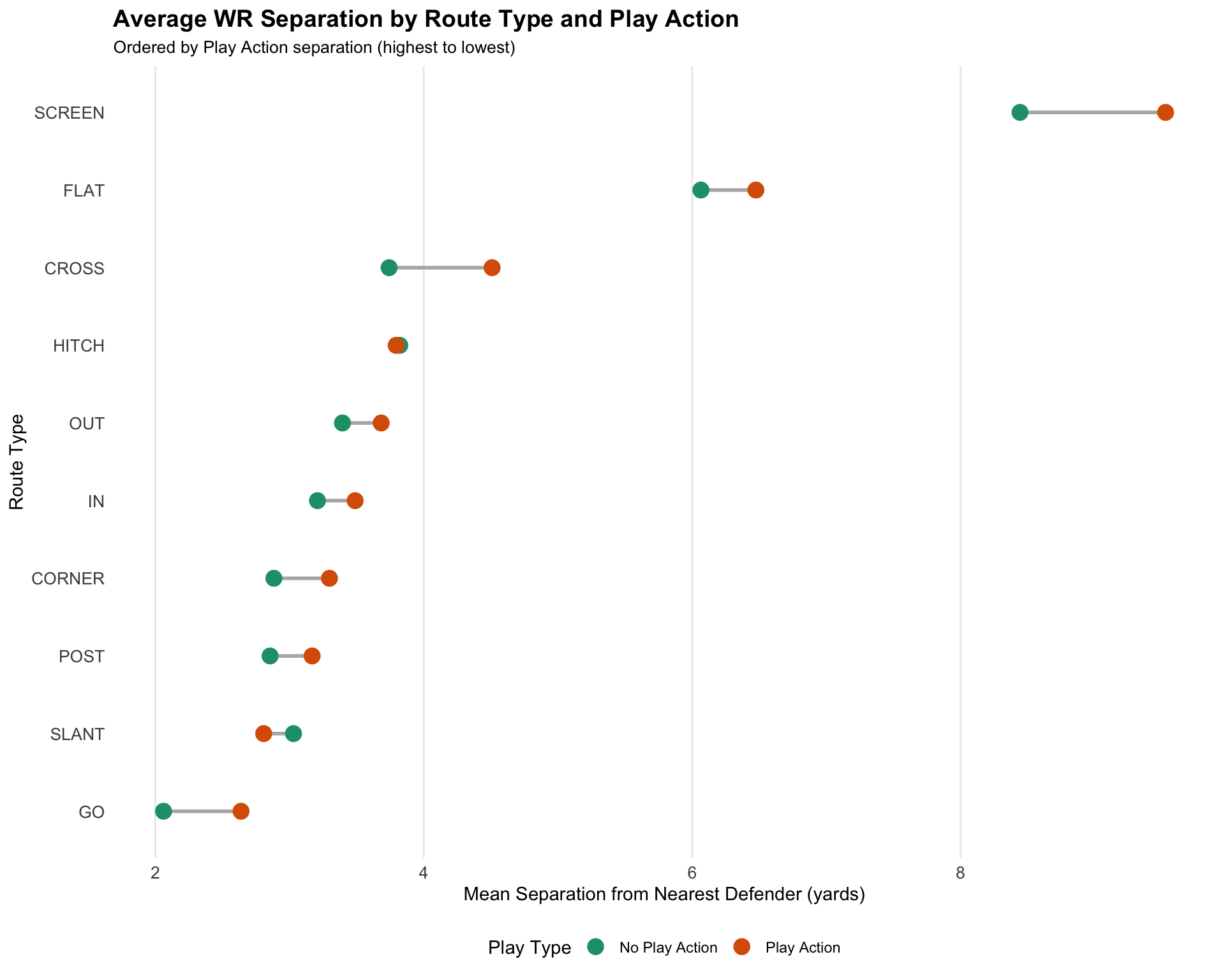
library(ggplot2)
library(dplyr)
library(reticulate)
library(lubridate)
in_week1 <- read.csv("data/train/input_2023_w01.csv")
in_week2 <- read.csv("data/train/input_2023_w02.csv")
in_week3 <- read.csv("data/train/input_2023_w03.csv")
in_week4 <- read.csv("data/train/input_2023_w04.csv")
in_week5 <- read.csv("data/train/input_2023_w05.csv")
in_week6 <- read.csv("data/train/input_2023_w06.csv")
in_week7 <- read.csv("data/train/input_2023_w07.csv")
in_week8 <- read.csv("data/train/input_2023_w08.csv")
in_week9 <- read.csv("data/train/input_2023_w09.csv")
in_week10 <- read.csv("data/train/input_2023_w10.csv")
in_week11 <- read.csv("data/train/input_2023_w11.csv")
in_week12 <- read.csv("data/train/input_2023_w12.csv")
in_week13 <- read.csv("data/train/input_2023_w13.csv")
in_week14 <- read.csv("data/train/input_2023_w14.csv")
in_week15 <- read.csv("data/train/input_2023_w15.csv")
in_week16 <- read.csv("data/train/input_2023_w16.csv")
in_week17 <- read.csv("data/train/input_2023_w17.csv")
in_week18 <- read.csv("data/train/input_2023_w18.csv")
out_week1 <- read.csv("data/train/output_2023_w01.csv")
out_week2 <- read.csv("data/train/output_2023_w02.csv")
out_week3 <- read.csv("data/train/output_2023_w03.csv")
out_week4 <- read.csv("data/train/output_2023_w04.csv")
out_week5 <- read.csv("data/train/output_2023_w05.csv")
out_week6 <- read.csv("data/train/output_2023_w06.csv")
out_week7 <- read.csv("data/train/output_2023_w07.csv")
out_week8 <- read.csv("data/train/output_2023_w08.csv")
out_week9 <- read.csv("data/train/output_2023_w09.csv")
out_week10 <- read.csv("data/train/output_2023_w10.csv")
out_week11 <- read.csv("data/train/output_2023_w11.csv")
out_week12 <- read.csv("data/train/output_2023_w12.csv")
out_week13 <- read.csv("data/train/output_2023_w13.csv")
out_week14 <- read.csv("data/train/output_2023_w14.csv")
out_week15 <- read.csv("data/train/output_2023_w15.csv")
out_week16 <- read.csv("data/train/output_2023_w16.csv")
out_week17 <- read.csv("data/train/output_2023_w17.csv")
out_week18 <- read.csv("data/train/output_2023_w18.csv")
supplementary <- read.csv("data/supplementary_data.csv")
# Combine all weekly input data
all_weeks <- bind_rows(
in_week1, in_week2, in_week3, in_week4, in_week5, in_week6,
in_week7, in_week8, in_week9, in_week10, in_week11, in_week12,
in_week13, in_week14, in_week15, in_week16, in_week17, in_week18
)
# For each play, get the final frame (ball arrival)
ball_arrival_frames <- all_weeks |>
group_by(game_id, play_id) |>
summarise(arrival_frame = max(frame_id), .groups = "drop")
# Filter to ball arrival frame
all_weeks_ball_arrival <- all_weeks |>
inner_join(ball_arrival_frames, by = c("game_id", "play_id")) |>
filter(frame_id == arrival_frame)
# Get defenders at ball arrival
defenders <- all_weeks_ball_arrival |>
filter(player_role == "Defensive Coverage") |>
select(game_id, play_id, nfl_id, x, y) |>
rename(defender_id = nfl_id, defender_x = x, defender_y = y)
# Get only targeted receivers at ball arrival
# (excluding other route runners to avoid inflated separation from defenders moving toward target)
receivers_and_runners <- all_weeks_ball_arrival |>
filter(player_role == "Targeted Receiver") |>
select(game_id, play_id, frame_id, nfl_id, x, y, player_role, player_position)
# Calculate nearest defender for each targeted receiver
nearest_defenders <- receivers_and_runners |>
inner_join(defenders, by = c("game_id", "play_id"), relationship = "many-to-many") |>
mutate(distance = sqrt((x - defender_x)^2 + (y - defender_y)^2)) |>
group_by(game_id, play_id, frame_id, nfl_id) |>
slice_min(distance, n = 1, with_ties = FALSE) |>
ungroup() |>
select(game_id, play_id, frame_id, nfl_id,
nearest_defender_id = defender_id,
nearest_defender_distance = distance)
# Add nearest_defender_id and nearest_defender_distance columns to all_weeks
all_weeks <- all_weeks |>
left_join(nearest_defenders, by = c("game_id", "play_id", "frame_id", "nfl_id"))
# Filter all_weeks to only include rows where nearest_defender columns are not NA
# (i.e., only receivers/route runners)
all_weeks_filtered <- all_weeks |>
filter(!is.na(nearest_defender_id) & !is.na(nearest_defender_distance))
# Replace all_weeks with the filtered version
all_weeks <- all_weeks_filtered
# Calculate average separation per receiver
# Group by nfl_id and player name, count routes, and calculate average separation
receiver_separation <- all_weeks |>
filter(player_position == "WR") |>
group_by(nfl_id, player_name, player_position) |>
summarise(
routes_ran = n_distinct(paste(game_id, play_id)),
avg_separation = mean(nearest_defender_distance, na.rm = TRUE),
.groups = "drop"
) |>
filter(routes_ran >= 50) |>
arrange(desc(avg_separation)) |>
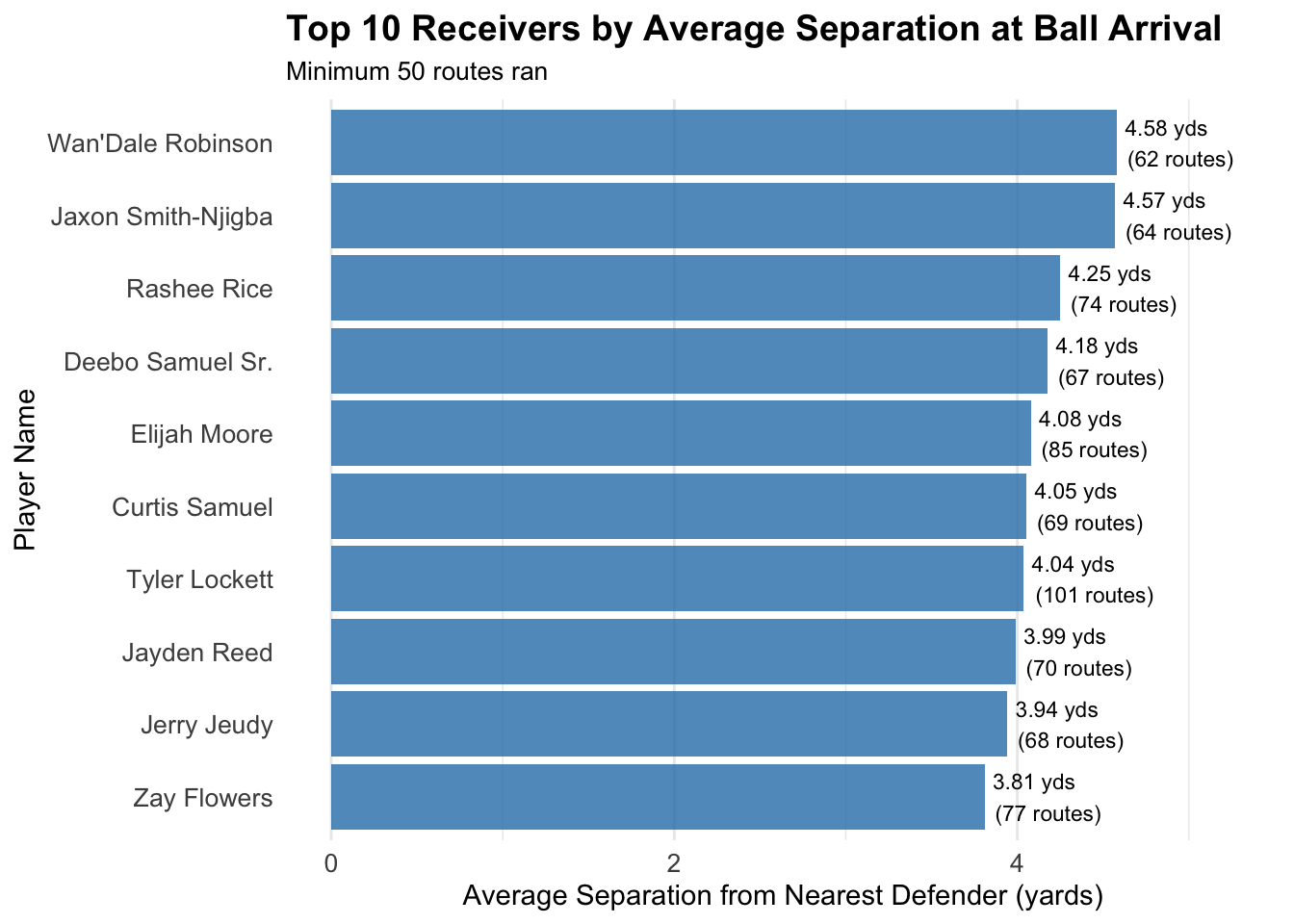
head(10)
# Create a bar plot
ggplot(receiver_separation, aes(x = reorder(player_name, avg_separation), y = avg_separation)) +
geom_bar(stat = "identity", fill = "#2c7fb8", alpha = 0.8) +
geom_text(aes(label = paste0(round(avg_separation, 2), " yds\n(", routes_ran, " routes)")),
hjust = -0.1, size = 3) +
coord_flip() +
labs(
title = "Top 10 Receivers by Average Separation at Ball Arrival",
subtitle = "Minimum 50 routes ran",
x = "Player Name",
y = "Average Separation from Nearest Defender (yards)"
) +
theme_minimal() +
theme(
plot.title = element_text(face = "bold", size = 14),
plot.subtitle = element_text(size = 10),
axis.text = element_text(size = 10),
panel.grid.major.y = element_blank()
) +
ylim(0, max(receiver_separation$avg_separation) * 1.15)