Code
library(ggplot2)
library(dplyr)
library(reticulate)
library(tidyr)
in_week1 <- read.csv("data/train/input_2023_w01.csv")
in_week2 <- read.csv("data/train/input_2023_w02.csv")
in_week3 <- read.csv("data/train/input_2023_w03.csv")
in_week4 <- read.csv("data/train/input_2023_w04.csv")
in_week5 <- read.csv("data/train/input_2023_w05.csv")
in_week6 <- read.csv("data/train/input_2023_w06.csv")
in_week7 <- read.csv("data/train/input_2023_w07.csv")
in_week8 <- read.csv("data/train/input_2023_w08.csv")
in_week9 <- read.csv("data/train/input_2023_w09.csv")
in_week10 <- read.csv("data/train/input_2023_w10.csv")
in_week11 <- read.csv("data/train/input_2023_w11.csv")
in_week12 <- read.csv("data/train/input_2023_w12.csv")
in_week13 <- read.csv("data/train/input_2023_w13.csv")
in_week14 <- read.csv("data/train/input_2023_w14.csv")
in_week15 <- read.csv("data/train/input_2023_w15.csv")
in_week16 <- read.csv("data/train/input_2023_w16.csv")
in_week17 <- read.csv("data/train/input_2023_w17.csv")
in_week18 <- read.csv("data/train/input_2023_w18.csv")
out_week1 <- read.csv("data/train/output_2023_w01.csv")
out_week2 <- read.csv("data/train/output_2023_w02.csv")
out_week3 <- read.csv("data/train/output_2023_w03.csv")
out_week4 <- read.csv("data/train/output_2023_w04.csv")
out_week5 <- read.csv("data/train/output_2023_w05.csv")
out_week6 <- read.csv("data/train/output_2023_w06.csv")
out_week7 <- read.csv("data/train/output_2023_w07.csv")
out_week8 <- read.csv("data/train/output_2023_w08.csv")
out_week9 <- read.csv("data/train/output_2023_w09.csv")
out_week10 <- read.csv("data/train/output_2023_w10.csv")
out_week11 <- read.csv("data/train/output_2023_w11.csv")
out_week12 <- read.csv("data/train/output_2023_w12.csv")
out_week13 <- read.csv("data/train/output_2023_w13.csv")
out_week14 <- read.csv("data/train/output_2023_w14.csv")
out_week15 <- read.csv("data/train/output_2023_w15.csv")
out_week16 <- read.csv("data/train/output_2023_w16.csv")
out_week17 <- read.csv("data/train/output_2023_w17.csv")
out_week18 <- read.csv("data/train/output_2023_w18.csv")
supplementary <- read.csv("data/supplementary_data.csv")
# Create offense_win_probability_added and defense_win_probability_added columns
# Logic: If possession_team == home_team, offense gets home WPA, defense gets visitor WPA
# If possession_team == visitor_team, offense gets visitor WPA, defense gets home WPA
supplementary <- supplementary |>
mutate(
offense_win_probability_added = ifelse(
possession_team == home_team_abbr,
home_team_win_probability_added,
visitor_team_win_probility_added
),
defense_win_probability_added = ifelse(
possession_team == home_team_abbr,
visitor_team_win_probility_added,
home_team_win_probability_added
)
)
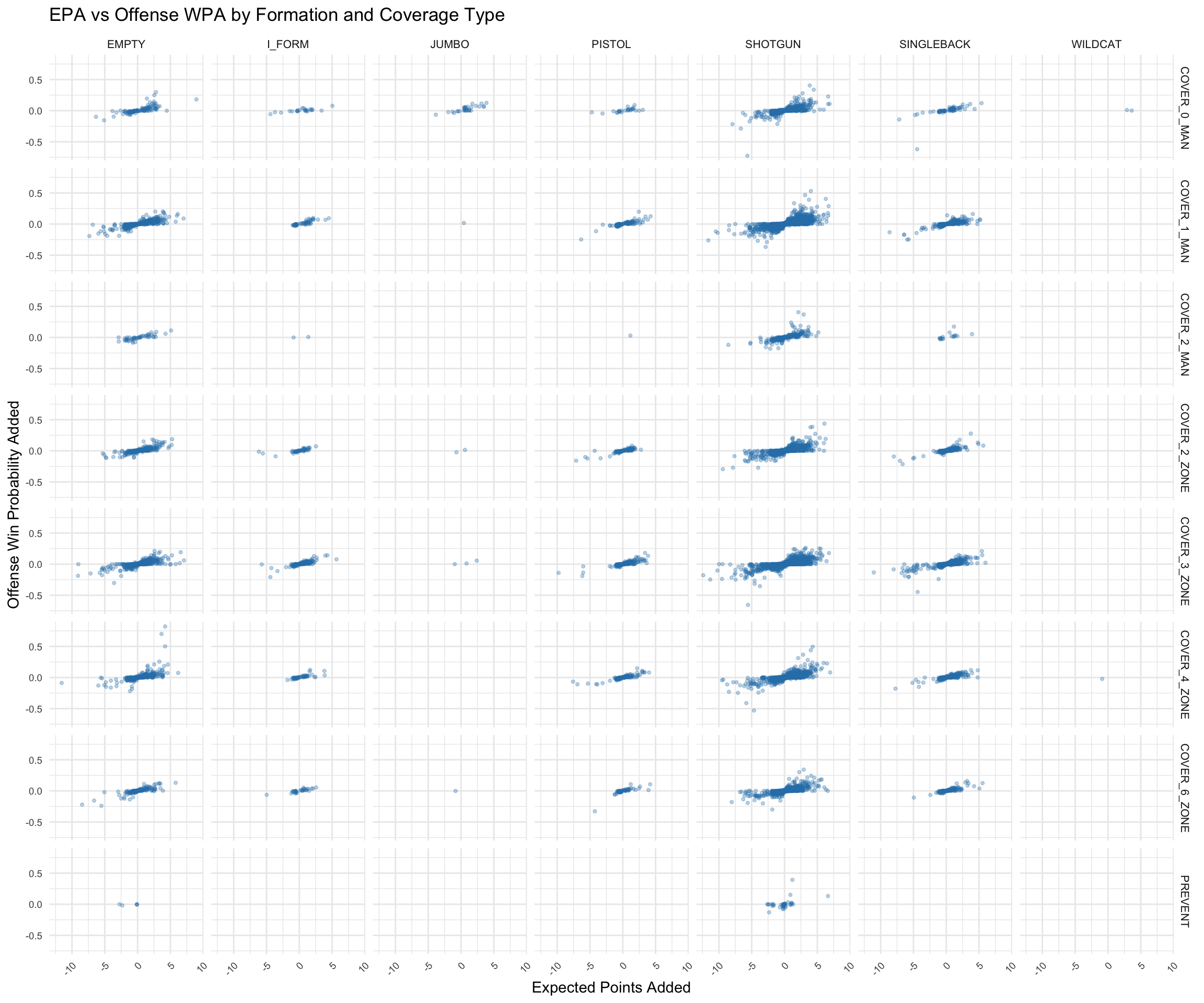
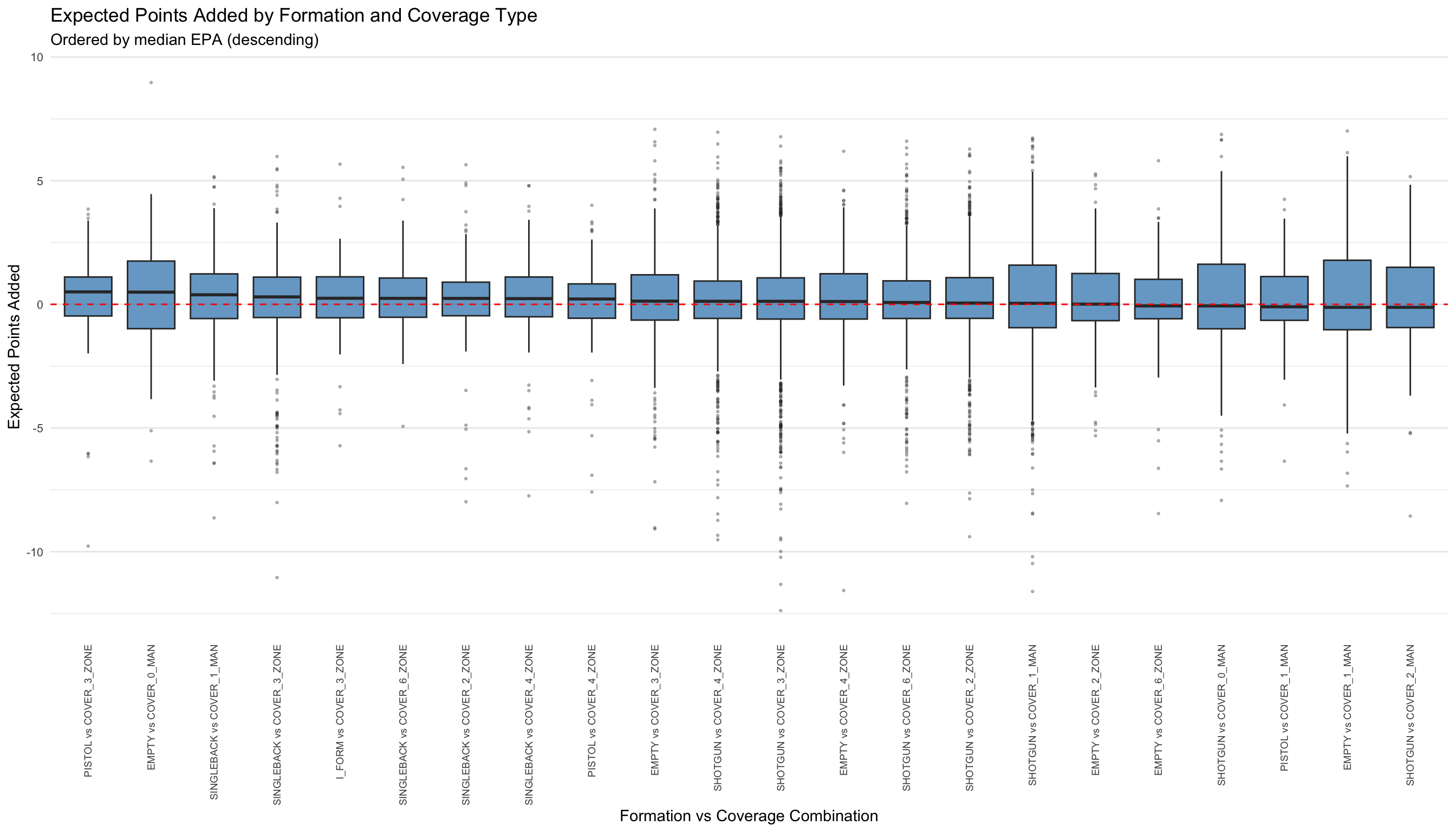
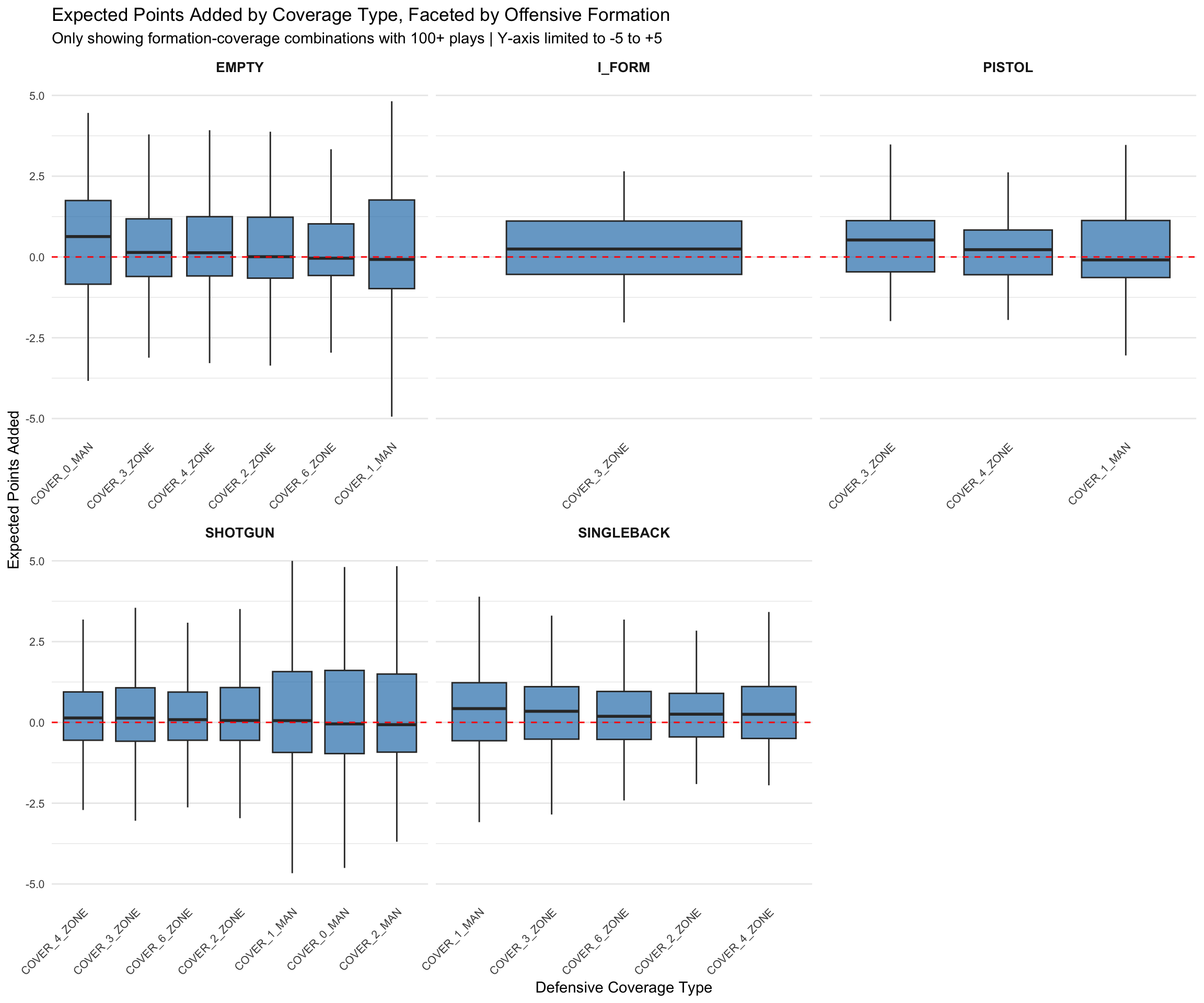
# Remove NA values for the variables we're plotting
supp_clean <- supplementary |>
filter(!is.na(offense_formation) &
!is.na(team_coverage_type) &
!is.na(expected_points_added) &
!is.na(offense_win_probability_added))
# Get all unique combinations of offense_formation and team_coverage_type
formations <- unique(supp_clean$offense_formation)
coverages <- unique(supp_clean$team_coverage_type)